Steps for solving a topology optimization problem in ATOMiCS¶
The users just need to modify the run_files (see Examples library) to perform a topology optimization.
We present an introduction to the settings of the run_files below.
ATOMiCS supports FEniCS built-in meshes as well as external mesh of .vtk or .stl type from GMSH, pygmsh or other mesh generation tools.
1.1 FEniCS built-in meshes:
The documentations for FEniCS built-in meshes can be found here.
1.2. External mesh:
We use meshio to convert the external mesh to the formats that FEniCS accepts (.vtk or .stl for now). GMSH can be installed from here.
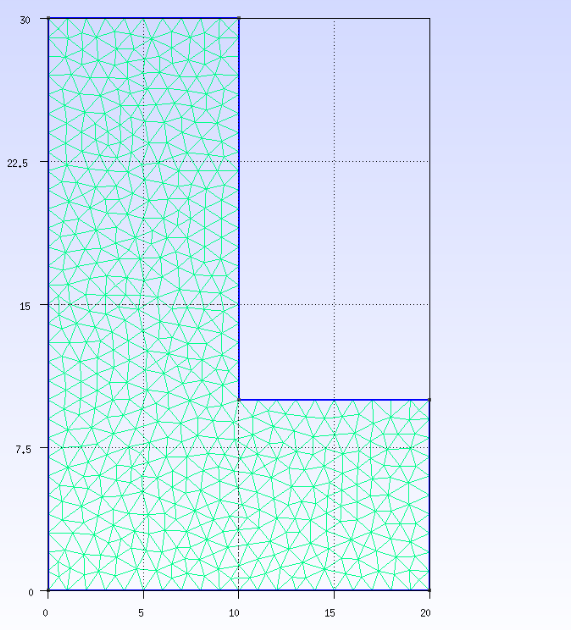
An example mesh generated from GMSH GUI is shown below:
Here is one of the GMSH tutorials you can find online.
One important thing to note is that you need to try to generate meshes that are close to the same size
to make the filter to work properly.
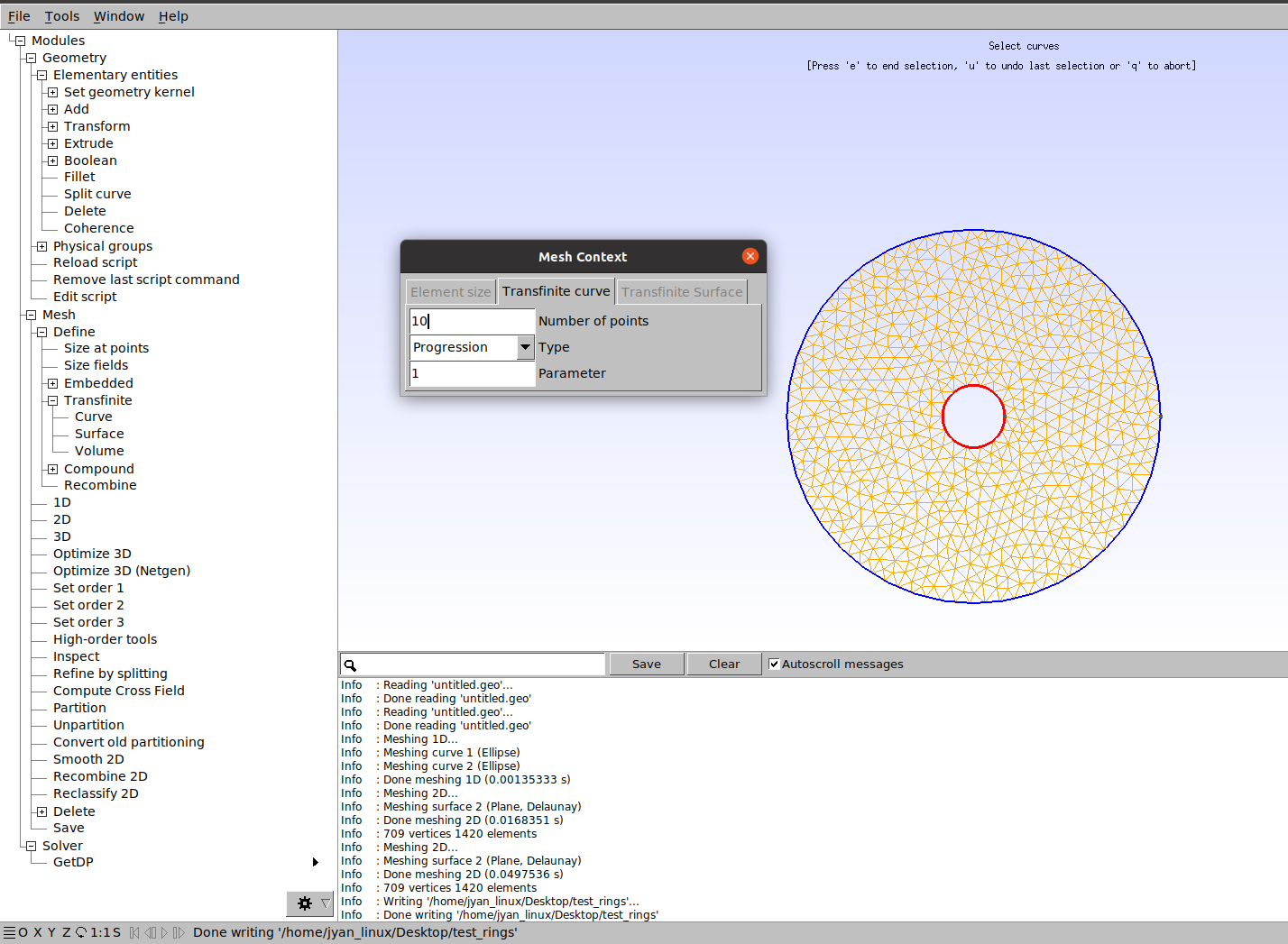
This can be done in a couple of ways in GMSH.
One way to do it is Mesh->Transfinite->line/curve and tune the number of points on different sides.
After generating the mesh, we need to export the mesh into .vtk or .stl format (ctrl+e for GMSH) in the same folder as your run_file.
Then, we use meshio to convert the file to .vtk or .stl format using the code below (see Topology optimization using external mesh)
# import the mesh file generated from your external toolimportmeshiofilename=<file_name>mesh=meshio.read(filename,file_format=<file_format># "vtk" or "stl" are tested)# convert the mesh into xmlmeshio.write_points_cells(<out_file_name>,# "fenics_mesh_l_bracket.xml"mesh.points,mesh.cells,)# set the mesh as input to the topology optimization problemmesh=df.Mesh(<out_file_name>)
GMSH and pygmsh may automatically generate 3D mesh even if you set it to 2D.
You can varify this by using d=len(displacements_function).
if d=3, you may want to convert this to 2D using the code below instead (see Case study II: battery pack topology optimizations).
(Importing os may cause some error for openmadon2file_name.py for visualizing the code structure.
If that happens, you can generate the mesh in a seperate python file. Then, just use the last line of code in the run file.)
We use FEniCS built-in functions to define boundary conditions for the topology optimization problems.
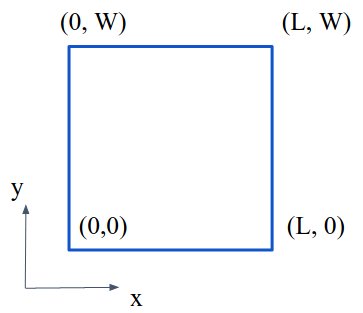
Below is a quick demonstration using a simple 2D square.
Note that the function_space.sub(0) here represents the x component of the function space.
If the function_space is for a displacements field, the bc_bottom is a sliding boundary condition to constrain the x displacements meaning the structure can only slide in y direction on the bottom boundary of the square.
While the bc_left is a clamped boundary meaning all the displacements on the left boundary are set to zeros.
The users can choose between a linear direct filter implemented in OpenMDAO and a FEniCS variational filter.
For now, we recommand the linear direct filter.
There are currently six options (fenics_direct, scipy_splu, fenics_krylov, fenics_krylov, petsc_gmres_ilu, scipy_cg, petsc_cg_ilu) for solving the total derivatives in AtomicsGrouplinear_solver.
We define three type of problems (problem_type) in AtomicsGroup: linear_problem, nonlinear_problem, nonlinear_problem_load_stepping.
Our default options are petsc_cg_ilu and nonlinear_problem for robustness and better precision for the total detivatives (if your petsc version is compatible).
But for small scale linear problem (or incompatibility of the petsc), we recommand fenics_direct (a direct solver) as the linear solver to solve the total derivatives, and choosing linear_problem as the problem_type.
There are two types of outputs: scalar output (a scalar on the entire mesh) and field output (a scalar on each element). The users need to define the output_form, and then add the output to the pde_problem.
We recommand using ParaView for the visualization of the optimizaiton results.
The users need to save the solution (at the end of the run_file).
#save the solution vectorifmethod=='SIMP':penalized_density=df.project(density_function**3,density_function_space)else:penalized_density=df.project(density_function/(1+8.*(1.-density_function)),density_function_space)df.File('solutions/displacement.pvd')<<displacements_functiondf.File('solutions/penalized_density.pvd')<<penalized_density
Then, the users can open the .pvd file using Paraview.
Advanced user may visualize the iteration histories by turning on the visualization option to True in the run_file (group=AtomicsGroup(...,visualization=True)).
We recommand Paraview-Python for genenerating the script to take a screenshot for each .pvd file. Then, using the script below to generate a video.
importsubprocessfromsubprocessimportcalldefmake_mov(png_filename,movie_filename):cmd='ffmpeg -i {} -q:v 1 -vcodec mpeg4 {}.avi'.format(png_filename,movie_filename)call(cmd.split())cmd='ffmpeg -i {}.avi -acodec libmp3lame -ab 384 {}.mov'\
.format(movie_filename,movie_filename)call(cmd.split())defmake_mp4(png_filename,movie_filename):# real time 130fps; two times slower 65fps; four times lower 37.5fpsbashCommand="ffmpeg -f image2 -r 65 -i {} -vcodec libx264 -y {}.mp4"\
.format(png_filename,movie_filename)process=subprocess.Popen(bashCommand.split(),stdout=subprocess.PIPE)output,error=process.communicate()png_filename='density_'+'%1d.png'movie_filename='mov'make_mov(png_filename,movie_filename)make_mp4(png_filename,movie_filename)